
欢迎来到《大语言模型提示词实战》的第一讲,看完整课程大纲点这里。
没有看过先导篇的会员朋友,先看先导介绍。
本课程前三节所有用户可免费阅读,办理会员点👇👇👇
订阅会员原价399元/年,当前限时特惠99元/年
在正式开始学习提示词之前,我们首先需要理解什么是大语言模型,一些相关概念,以及它的能力边界在哪里。这节课的内容会帮助你建立对 AI 的正确认知,这对后续如何更好地使用AI至关重要。
一、AI 模型其实是”智能图书馆+贴心管理员”
要理解大语言模型,我们可以把它想象成一个超级图书馆:
想象一下,有一个巨大的图书馆,里面收藏了人类几乎所有公开的知识和信息。这个图书馆还配备了一位超级智能的图书管理员,他:
- 记住了图书馆里的所有内容
- 能迅速理解你的问题
- 会根据你的需求,快速整理相关的信息
- 并用你容易理解的方式表达出来
这就是大语言模型的本质 —— 它通过学习海量的文本数据(人类图书馆的藏书),形成了强大的语言理解和生成能力(图书管理员的服务)。
为什么说它”大”?这里的”大”主要体现在两个方面:
- 数据量大:
- 训练数据包含数十亿甚至数千亿字的文本
- 相当于一个人读完几百万本书的内容
- 覆盖了互联网上大量公开的文本信息
- 参数量大:
- 最新的模型往往有数千亿个参数
- 这些参数就像人脑中的神经连接
- 参数越多,模型的理解和生成能力通常越强
二、主流大模型
目前市面上有很多大语言模型,我们来认识几个最常用的:
1. 国外的
- GPT-4 模型是当今最强大的人工智能大模型
- Claude-3.5 目前也发展不错,善于处理长文本
2. 国内的
- 百度的文心一言、阿里的通义千问、字节的豆包、腾讯的混元、创业公司月之暗面的 kimi 等
- 各公司基本盘业务不同,所以这些模型各有特色和专长,选择时可以根据具体需求来决定
- 国内大模型产品个人用户基本免费
3. 大模型和大模型应用的区别
- 我们有时候会接触到不同术语,比如 GPT 模型、GPT-4 和 ChatGPT 等。GPT 模型是一种由 OpenAI 公司开发的大语言模型(LLM),用来处理和生成自然语言。GPT-4 是该模型的第四代版本,具有更高的语言理解和生成能力,而 ChatGPT 是基于该模型开发的具体应用,通常以网页或 App 的形式呈现,是用户可以直接使用的人机对话平台。可以理解为,ChatGPT 的后台运行着 GPT 模型
- ChatGPT 本身也有多个版本。在聊天界面中我们可以选择不同的模型版本,如 ChatGPT-4 和 ChatGPT-4o,它们在背后支持的模型版本和推理速度上有所差异
- 其它公司的大模型及大模型应用道理一样
三、重要基础概念
在开始使用AI之前,让我们先了解几个重要的基础概念,这些概念会帮助你更好地理解和使用AI模型。
1. LLM是什么?
LLM(Large Language Model)就是”大语言模型”的英文缩写。之所以叫”语言模型”,是因为:
- 它的核心功能是理解和生成人类语言
- 它通过”预测下一个词应该是什么”来工作
- 这就像你在玩”接龙”游戏,但它玩得比人类要好得多
举个例子: 当你输入”中国的首都是…”,模型会根据学习到的知识,非常自然地补充”北京”。
2. Token(标记)是什么?
大语言模型在训练时,被投喂的数据,是大量文本数据,如大量的出版物、网页等。不同人类语言的词汇量和词汇规则不同,有些语言里一个意思可能只需要一个字,而在其他语言可能需要多个字母拼成一个单词。用 token 切分,可以让模型对不同语言更灵活地处理。token 可以跨语言把不同的词汇、词组拆分成小块,这样即使遇到不常见的单词,模型也可以用 token 的组合来理解意思。
举个例子:拼装一套乐高玩具。有些人喜欢先买整套玩具,而有些人只买各种基础的乐高小块,自己拼出各种新造型。
把句子按单词处理,就像是直接买整套玩具,每个“单词”就是一个整套的造型。要是我们碰到一个新的造型,商店里可能没有卖的,我们就无法拼出那个造型了。
而把句子按 token 处理,就像是买很多基础的小块,比如各种形状的“积木块”。这样,即使碰到没有见过的造型,我们也能用这些基础积木块组合出来。这样灵活性更高,也不用记住所有可能的造型,只需要记住一些基础的块和组合方法就行了。所以,模型使用 token,就像拼乐高用基础积木块,它能更灵活地应对各种语言的表达和变化。
Token 是 AI 处理文本的基本单位,理解它很重要:
- 中文中,一个汉字通常是一个 token
- 英文中,一个单词可能被分成多个 token
- 标点符号也会占用 token
- token 数量直接关系到处理成本和速度
例如:”你好,AI!” 这句话大约包含5个 token:
- “你”(1个 token)
- “好”(1个 token)
- “,”(1个 token)
- “AI”(1个 token)
- “!”(1个 token)
为什么要关心token?
- 模型对输入词长度有限制(以 token 计算),模型的输出词汇也会计算 token 量。如 GPT-4-8k,支持最多大概 8k 个 token
- 使用 token 越多,成本越高。免费模型每天有 token 用限制,不过我们处理日常生活类的任务一般是够用的,不用担心 token 的限制。如果被限制了,这么多大模型换一个用就是
- 大模型在生成内容时,本质上是基于概率的。它通过训练大量的数据,学习到词语或词汇片段(token)在不同上下文中的出现概率。每次生成内容时,它会根据上下文预测下一个 token 的概率分布,选出最可能的 token,逐步构建完整的输出。举个可能不太恰当的例子说明,早上起床后要吃早饭,我们大脑里飘过很多早餐选项,“今天早饭吃…”,面包?包子?三明治?米粉?选择吃面包/包子/三明治/米粉,其实是有概率的,如果你做过自己早饭食物统计的话。如果按最高概率选,每天吃的都是一样的,早饭会很单一,没有灵活性和创造性。怎么解决大模型生成下一个 token 词的概率呢?看下面温度值的概念。


(图示 token,每行每个色块是一个 token)
3. Temperature(温度)是什么?
Temperature 是控制 AI 回答”创造性”的一个重要参数:
低温度(接近0)
- 回答更确定、一致
- 适合事实性回答
- 例如:解答数学题、查询知识
高温度(接近1)
- 回答更具创造性
- 可能产生意想不到的结果
- 适合创意写作、头脑风暴
举个例子: 假设让 AI 写一个”春天”的句子
- 低温度:春天来了,花儿开了,很美丽。(相对保守)
- 高温度:春姑娘踮着轻盈的脚尖,洒下一地金色的阳光和粉色的花瓣。(更有创意)
实际使用如 ChatGPT 这类对话应用时,并不需要我们手动调节温度值,也没有地方可调。但是我们通过 api 接口开发调用大模型时,是可以通过接口传参调整的。
4. 模型参数量是什么?
参数量是衡量AI模型”大脑容量”的指标:
- 参数越多,模型理解和生成能力通常越强
- 但参数量增加也意味着更高的使用成本
- 参数量不是唯一决定因素,模型设计和训练质量同样重要
一些常见模型的参数量参考:
- GPT-3.5:约1750亿参数
- GPT-4:参数量未公开,但估计超过1万亿
- Claude:参数量未公开,但性能与GPT-4相当
参数量的形象理解: 如果把参数比作”大脑神经元”:
- 10亿参数 ≈ 一只猫的大脑神经元数量
- 1750亿参数 ≈ 2000个人类大脑的神经元数量
但请记住:参数量不等于智能程度,就像大脑体积不等于智商。
6. 实用使用小贴士
- 注意控制输入文本长度(token数)
- 如果调用接口,根据任务类型调整temperature
- 创意任务:使用较高 temperature(0.7-0.9)
- 分析任务:使用较低 temperature(0.1-0.3)
- 选择合适的厂家和模型
- 简单任务选择参数量小的模型(省钱)
- 复杂任务选择参数量大的模型(更强)
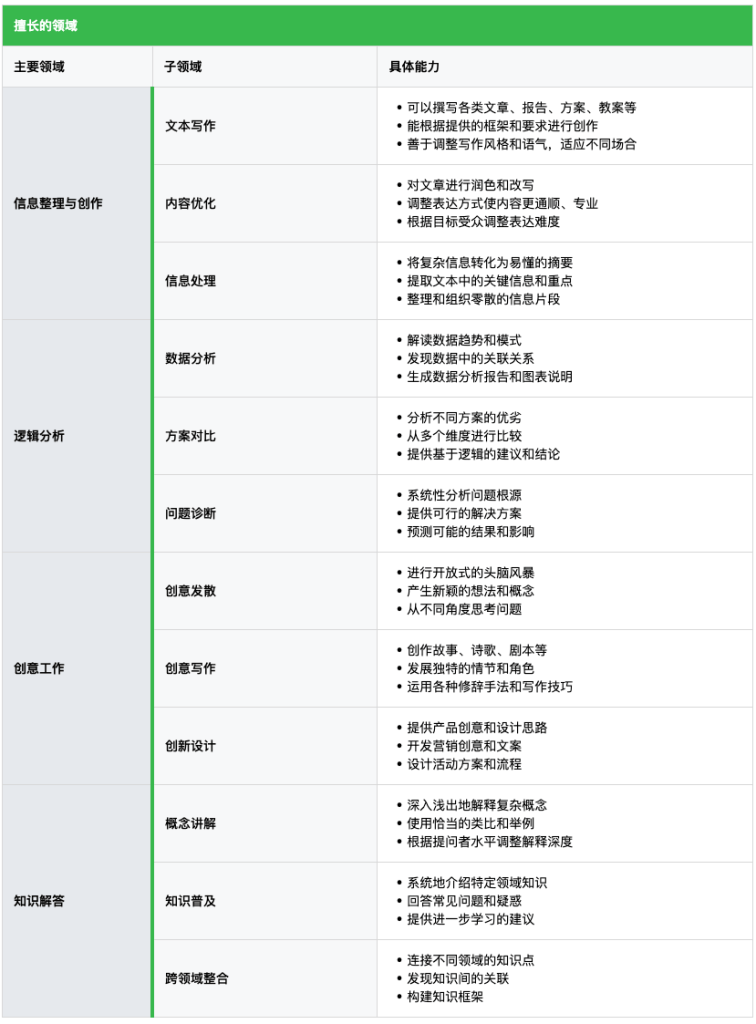
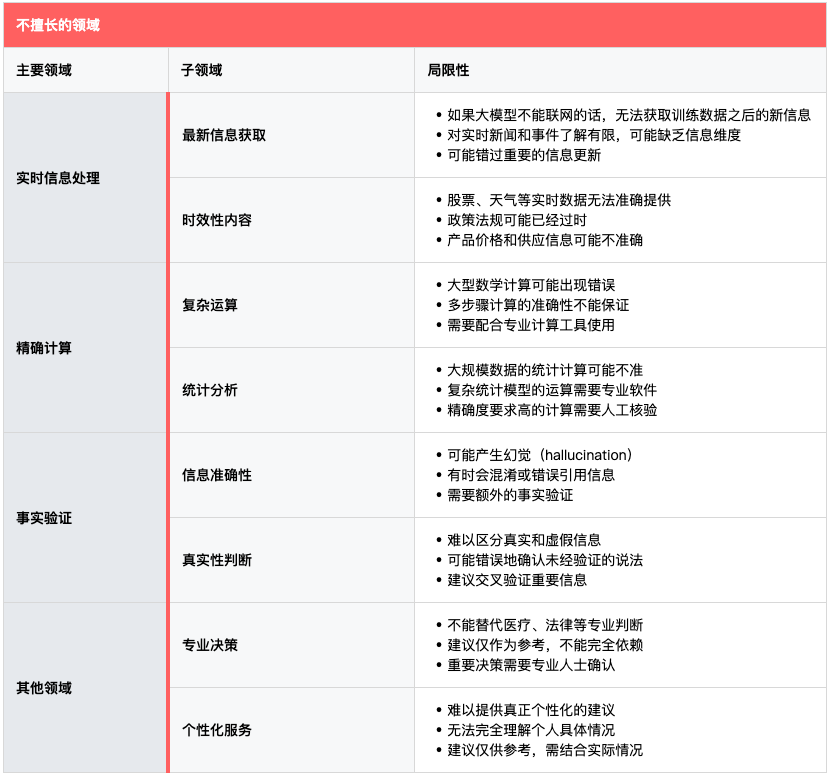
四、能力边界:既要认识潜力,也要明白局限
要充分发挥大语言模型的价值,关键在于准确理解它的能力边界。每个工具都有其特定的用途,大语言模型也有其擅长和不擅长的领域。正确认识这些边界,既能让我们避免盲目期待,也能帮助我们更好地利用大模型的优势。
五、实践练习:初次对话体验
让我们通过一些简单的练习,来实际体验AI的能力:
练习1:基础对话
尝试问一些简单的问题:
- “什么是人工智能?”
- “请解释下光合作用的过程”
- “帮我写一首简单的诗”
观察AI的回答方式和内容质量。
练习2:能力边界测试
尝试一些边界性的问题:
- 问一个需要最新信息的问题

- 问大模型他的知识库截止日期

- 问大模型他是否能上网实时搜索

- 让它进行复杂数学计算

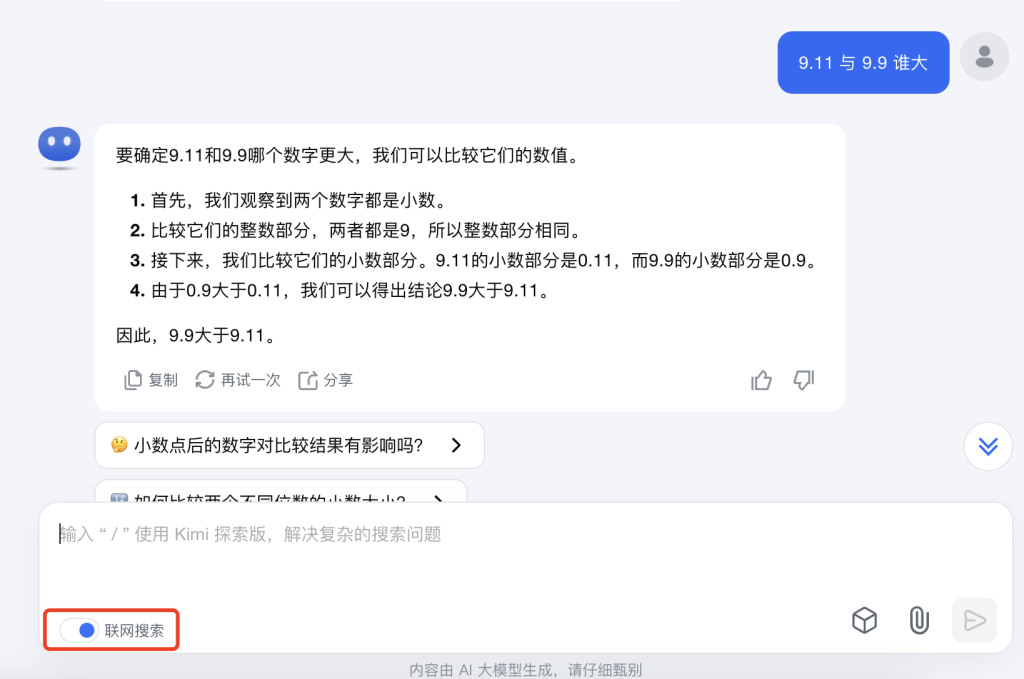
(使用 kimi )
观察AI在这些情况下的表现,多试试几个不同的大模型产品。
下一讲预告
下一讲我们将学习”提示词的基本概念“,了解如何更好地和AI对话。建议大家自己多花些时间和AI对话,积累一些实际体验,这样下一节课会更容易理解。
本讲小贴士
记住:AI是工具,不是魔法。它的强大和局限都源于其本质 —— 一个基于统计学习的语言模型。正确认识这一点,才能更好地利用它。
如果你在实践中遇到任何问题,欢迎联系课程作者交流讨论!

本课程前三节所有用户可免费阅读,办理会员点👇👇👇
订阅会员原价399元/年,当前限时特惠99元/年
本文部分素材来自网络,侵删请联系站长。
扫码关注本站公众号/加入知识星球,订阅更多精彩内容


